Japan Rook Meetup #2
はじめに
今回はリモートでの開催だったJapan Rook Meetup #2に関するブログ枠です。基本的に、意見ほぼなしのまとめです。GlusterFS とかはなんとなく触ったことがあるのですが、Rook とか Ceph とかはほぼ触ったことがなかったので、新鮮に勉強させていただきました。何かここが違うなど問題があれば、twitter 等でご指摘いただければと思います。
アジェンダ
ハッシュタグ
Youtube
内容
Rook 基礎・バージョンアップ @rev4t
そもそもどういう時に利用する物なのか
Kubernetes で外部ストレージを利用したい時
解決できること
k8s 上で Storage Operation を実現。storage は運用が大変だが、その自動化ができる。
Rook とは
CNCF。Operator + Custom Resouce で k8s 拡張可能。
また、沢山の Storage システムに対応したフレームワーク
- Ceph(Stable)
- EdgeFS(Stable)
- CockroachDB
- Cassandra
- NFS
- YugabyteDB
- minio
構成要素
- Rook Operator
実際にストレージのデプロイ・管理をしてくれるもの - Rook Discover
ストレージノードの変更等を検知して、Operator に伝える etc…
Version Up
● Rook(major version)
- 前提として、Ceph が正常に起動していることを確認
# cephのステータス確認
ceph status
- Rook の Control plane が正常に稼働していることを確認
- CRD と RBAC の更新
# e.g.
# https://github.com/rook/rook/blob/v1.2.0/cluster/examples/kubernetes/ceph/upgrade-from-v1.1-apply.yaml
kubectl apply -f upgrade-from-v1.1-apply.yaml
- fuse or rdb-ndb を使っている場合、Cephfs plugin。rdb plugin の update strategy を onDelete に変更
- Rook operator の update
# e.g. v1.2.5へ
kubectl -n $ROOK_SYSTEM_NAMESPACE set image deploy/rook-ceph-oeprator rook-ceph-operator=rook/ceph:v1.2.5
- 更新されるまで、しばらく待つ
- fuse or rdb-ndb を使っている場合、CSI driver の pod を delete することで更新させる
- 最後に、CRD を更新
# e.g.
# https://github.com/rook/rook/blob/v1.2.0/cluster/examples/kubernetes/ceph/upgrade-from-v1.1-crds.yaml
kubectl apply -f upgrade-from-v1.1-crds.yaml
● Rook(minor version)
- image の version を更新するだけ。
# e.g. v1.2.5へ
kubectl -n $ROOK_SYSTEM_NAMESPACE set image deploy/rook-ceph-oeprator rook-ceph-operator=rook/ceph:v1.2.5
(注)Ceph の delete/create が伴う場合があるそう。
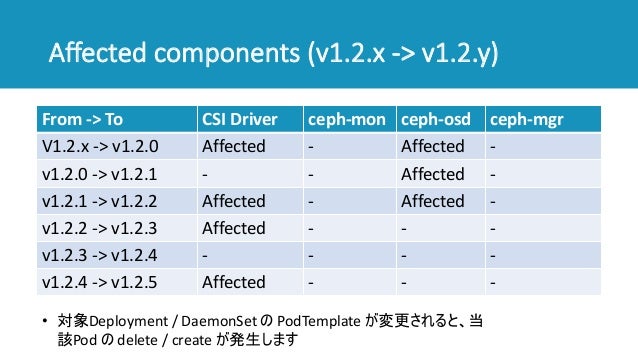
● Ceph(v14.2.4 -> v14.2.7)
- image の version を更新する。(image を更新すれば、あとは Rook Operator がやってくれる。)
- 完了するまで待つ。
# cephのステータス確認して、HEALTH_OKかどうか
ceph status
cluster: id: 3casefd74-edfg-2352-b54j-51jk12tj10
health: HEALTH_OK
● External Cluster
既存の Ceph Cluster に対して、Rook を用いた k8s との連携ができる。
■ メリット
- CSI Driver の運用管理のみを k8s で実施する形になり、k8s 側の運用コストを下げつつ、責任分界点を分けられる
- Rook Version Up の際に、Ceph Cluster に与えるサービス影響を完全に排除できる
- k8s networking による性能低下の影響をうけなくなる。
■ デメリット
- Rook の他に、Ceph のデプロイツールの導入をする必要が出てくる
■ 利用例
Rook + ceph-ansible
https://github.com/ceph/ceph-ansible
Summary
- 長期的な運用で、Storage Backend だけでなく、Rook Operaotr 自体の運用もしなくてはならない。
- Ceph の version がすごく楽になる。
- k8s 側の運用をシンプルにしたい場合は、ceph-ansible + Rook external cluster が良さそう。
質疑応答
Q. Ceph OSD の update で、node を変更しない以外のパターン以外で、新規の node に migration をかけることは可能か?
A. 検証していないが、多分できると思っている。
Q. Control Plan の upgrade する時に、実際にデータアクセスに影響があるということでしょうか?
A. Ceph OSD の pod を再起動されることになるので、クライアントからのリクエストの latency が高くなるだろうと思っている。影響の少ない時間帯で実施するなどの対応が必要だろうと思っている。
Rook/Ceph upstream 最新状況 @satoru_takeuchi
目次
- 前提知識: OSD 作成方法
- Rook 最新安定版の新機能
- Rook 次期安定版の開発状況
- Rook を取り巻く状況
1. 前提知識: OSD 作成方法
OSD の作成方法には大きく2つの方法があるとのこと
● 1.1. 従来の方法
OSD の設定にノード上のデバイスを直接指定する
- これだと、Rook/Ceph cluster 管理者にハードウェア構成の知識が必要
- さらに、デバイス名直接指定しているので、自前で cluster を構築する必要がある
● 1.2. OSD on PVC v1.1~
OSD の設定に PVC template を指定する。それを受けて、CSI driver が PV を作成する。Cluster 管理者は OSD pod がどこにあるかを気にしなくて良いさらに、デバイスの管理もしなくて良くなる。
2. Rook 最新安定版の新機能
● 2.1. OSD on PVC で LV サポート
- OSD on PVC でロジカルボリューム(LV)対応した(サイボウズ作)
■ 目的・背景
- ローカルの NVMe SSD 上に OSD を作成し、OSD を束ねて、Ceph Cluster を構築し、ブロックデバイス(RDB?)を提供したい
- 管理コスト削減のため、PV を dynamic provisioning したい。pv が欲しくなったら、dynamic な storage が欲しい。
■ 既存の課題
以下の条件を満たす CSI ドライバがない
- ローカルボリューム
- dynamic provisioning
- 実用レベルのものがない
つまり、デバイス追加は手作業で PV 作成する必要がある。
■ TopoLVM
- PVC の変更を検知して、PV を dynamiv provisioning してくれるやつ?
● 2.2. 従来方式で udev persistent name をサポート
v1.1 以前では、/dev 直下は気付いたら変わりうる。e.g. sda -> sdb
v1.2 以降では、新機能 devicePathFilter(サイボウズ作)
- こうすると、/dev 直下の device name は変わりうるのだが、by-path 名は変更されない
- そのため、データ破壊を防げる
● 2.3. その他変更
cech-crash collector
- daemon のクラッシュ情報を Ceph クラスタに保存できるので、トラブルシューティングに効果的
- デフォルトで有効
FileStore OSD が obsolete(既存の FileStore OSD はサポートし続ける)
3. Rook 次期安定版の開発状況
● 3.1. Failure domain をまたいだ OSD の均等分散配置
k8s の TopologySpreadConstraints 機能のサポート(OSD on PVC に必須)
■ TopologySpreadConstraints の目的
- ラック障害耐性
- ノード障害耐性
■ これまでの課題
OSD pod の偏りが生まれてしまい、ラックの障害耐性がない場合が有り得る。次期安定版から、対応予定で、これでようやく OSD on PVC が使えるものとなると思っている。
● 3.2. OSD on LV-backed PVC のテスト追加
- Rook は PR マージ時、テスト全パスが必須。
しかし、3 つの壁が。。。
■ 壁 1: master で OSD on LV-backed PVC が動かない
- この PR でリグレッションが発生 https://github.com/rook/rook/pull/4435
- Issue 発行 https://github.com/rook/rook/issues/5075
- CI 重要!!!!
■ 壁 2: テストがテスト環境を破壊
- テスト冒頭で全 LV/VG/PV を強制削除
- PR マージ待ち https://github.com/rook/rook/pull/4966
■ 壁 3: ローカル環境でテストがパスしない
調査中
● 3.3. FileStore の新規作成が不可能に
obsolute ではなく、不可能へ。
● 3.4. ストレージプロバイダ
- 新しいストレージプロバイダなし
- minio のコードが削除(メンテされていないから。)
● 3.5. その他の課題
コア部分と前ストレージプロバイダが同じリポジトリ管理しているので、開発がしにくい
- kubernetes と storage plugin を別リポジトリを分けた話と同じ感じ。
● 3.6. 今後の貢献予定
- テストの充実化
- 暗号化デバイス上の OSD
- バグ解決
4. Rook を取り巻く状況
● 4.1. プロジェクトの成熟度
- 現在は、Incubating
- もうちょっとで、卒業するかも? https://github.com/cncf/toc/pull/366
● 4.2. Rook/Ceph を使う製品
- Red Hat OpenShift Container Storage4(GA・2020-01-15)
- Containerized SUSE Enterprise Storage on CaaSP(Tecknical preview)
5. 参考リンク
- ストレージオーケストレーター Rook へのサイボウズのコミット方針
- Kubernetes でローカルストレージを有効活用しよう
- Rook - Graduation Proposal
- 賢く「散らす」ための Topology Spread Constraints
質疑応答
Q. TopoLVM に関して、LVM のレイヤーを declaretive なやり方で、VG?を作ってくれるものという認識であっていますでしょうか?
A. はい。その通りです。Storage Class で TopoLVM のものを指定していただければ、LV を勝手に切ってくれて、それをブロックデバイス、ないし、ファイルシステムとして利用できるものです。
Q. FileStore が obsolute になって、BlueStore への移行がこれから出てくると思うのだが、マイグレーションパスの開発は進んでいるのでしょうか?
A. 現在、ドキュメント整備中です。基本的には、そのドキュメントがみてやっていただければ良いようになっていく予定です。
Rook-Ceph で External Cluster を利用する @FUTA_0203
本日お話しすること
- Rook-Ceph External Cluster の概要
- Rook-Ceph External Cluster の利用方法
- Rook-Ceph External Cluster 利用時の注意点
● 1. Rook-Ceph External Cluster の概要
Rook-Ceph を構築したクラスター外に存在する、Ceph クラスターのストレージリソースを利用すること
- local: k8s(Rook) cluster
- external: Ceph cluster
■ 本機能の背景
- Rook ver 1.1 から利用可能
- 基本的には、k8s 内の storage を利用する想定だった
- しかし、そうではない、ユースケースもあったため。
そうではないユースケースとは…
- 既存 Ceph Cluster が存在する
- 1 つの Ceph クラスターのリソースを複数 k8s で利用したい
- 単純に storage を分離したい
■ Rook-Ceph クラスター構築(通常)
# e.g. v1.2
git clone --single-branch --branch release-1.2 https://github.com/rook/rook.git
cd cluster/examples/kubernetes/ceph
1. kubectl create -f common.yaml
2. kubectl create -f operator.yaml
3. kubectl create -f cluster-test.yaml
https://rook.io/docs/rook/v1.2/ceph-quickstart.html
■ Rook-Ceph クラスター構築(external cluster)
# e.g. v1.2
git clone --single-branch --branch release-1.2 https://github.com/rook/rook.git
cd cluster/examples/kubernetes/ceph
1. kubectl create -f common.yaml
2. kubectl create -f operator.yaml
3. kubectl create -f common-external.yaml
4. ConfigMap/Secretリソースに外部のCeph clusterの情報としていれる
- namespace
- FSID
- client admin
- monitor endpoint
5. kubectl create -f cluster-external.yaml
クラスター構築後は
- local: OSD / MON / MGR は存在しない
- External: State が、Created ではなく、Connected の状態になる
● 2. Rook-Ceph External Cluster の利用方法
- ストレージリソースを用意する際、local cluster 側の操作のみで完結できるのはよき。
● 3. Rook-Ceph External Cluster 利用時の注意点
- 1 番気をつけた方がいいのは、Ceph バージョンかな?
- configmap の修正が必要なのは、嫌だね。(いずれに、新しく最新 version を構築する場合は関係なさそう。)
● 参考リンク
- Rook Doc - Ceph Cluster CRD #External Cluster
- GitHub - Rook and External Ceph Clusters
- GitHub Issues - External cluster details are not populated to configmap rook-ceph-csi-config
Rook-Ceph でいろいろベンチマークとってみる @japan_rook
Rook Ceph で IO 計測をする
● モチベーション
- IO 測るの楽しい!笑
- ストレージ直と Rook-Ceph を挟むとどれくらい変わるか
- 構成変更による IO の変化
● 環境
- worker は、Rook-Ceph と IO をかけるが同居するため、割と強めにしている。
- 一応、現時点で最新 version の組み合わせ。
● 遊び方
- FIO 3.13
- kubestone fio
- fio の Custom Resource が便利
- ここのQuick Start通りにやれば ok ってことかな?
- fio の pod から 100GB をマウント
- 時間の都合で、4K random read, 4K random write のみ
● 何を測るか
- 素の EBS(gp2)vs Rook-Ceph 3x replica RBD
- Ceph クラスタの OSD 数
- レプリカ数(一般的に、3x の replicas だが。)
■ 1. 素の EBS(gp2)vs Rook-Ceph 3x replica RBD
- 負荷が低い時の write は結構違う。EBS の方が速い
- 個人的には、それぞれ OSD を 3 つつけていて、並列に read ができるので、1 個の EBS から read するのと、3 個の EBS から読み込むよりも有利なので、Rook-Ceph の方が役に立つ(read 強い。)
■ 2. Ceph クラスタの OSD 数
■ 3. レプリカ数
- clush rule にしたがって、平均になるように、replica されている
- なので、利用される EBS の数は変わらない。
まとめ
質疑応答
Q. MIN_SIZE(Ceph pool の最小サイズ?)は同じにしているのかな?
A. 同じ一にしています。2x でも死んでも計測し続けられるようにしています。
Q. best practice で、1 SSD 1 device あたり 〇〇 OSD に良いみたいな指針をみた気がするのですが。そういう指針に沿うと良いとか有りますか?
A. 有効に使う 1 SSD に対して、1 OSD にしても、あまり IO がこなければもったいないので、2 とか 4OSD にした方が良いという話もあります。感覚としては、一旦、1 SSD に対して、1~2 OSD が良いかなと。NVMe みたいに、並列に Queue がバシバシ入るものなら、4,6OSD でも良いかなと。もう、その辺はどの程度の負荷になるか。容量にするか。によって、変えてもらえればと思います。
さいごに
オンラインイベント初だったが、発表の音声ログなど残っていれば、そんなに問題ないなと思ったりしました。